
Po skonfigurowaniu adresacji IP, routingu, DNS i DHCP przychodzi moment, w którym sama znajomość konfiguracji przestaje wystarczać. W praktyce równie ważne staje się to, żeby umieć sprawdzić, co właściwie dzieje się w systemie, gdy usługa nie startuje, klient nie dostaje odpowiedzi albo serwer odrzuca zapytania. I właśnie tutaj do gry wchodzą logi.
Logi rejestrują zdarzenia związane z działaniem systemu, usług, procesów i użytkowników. To one często jako pierwsze pokazują, dlaczego coś nie działa tak, jak powinno. Dzięki nim można sprawdzić, czy usługa uruchomiła się poprawnie, czy klient połączył się z serwerem, czy system odrzucił zapytanie albo czy pojawił się problem z uprawnieniami lub konfiguracją.
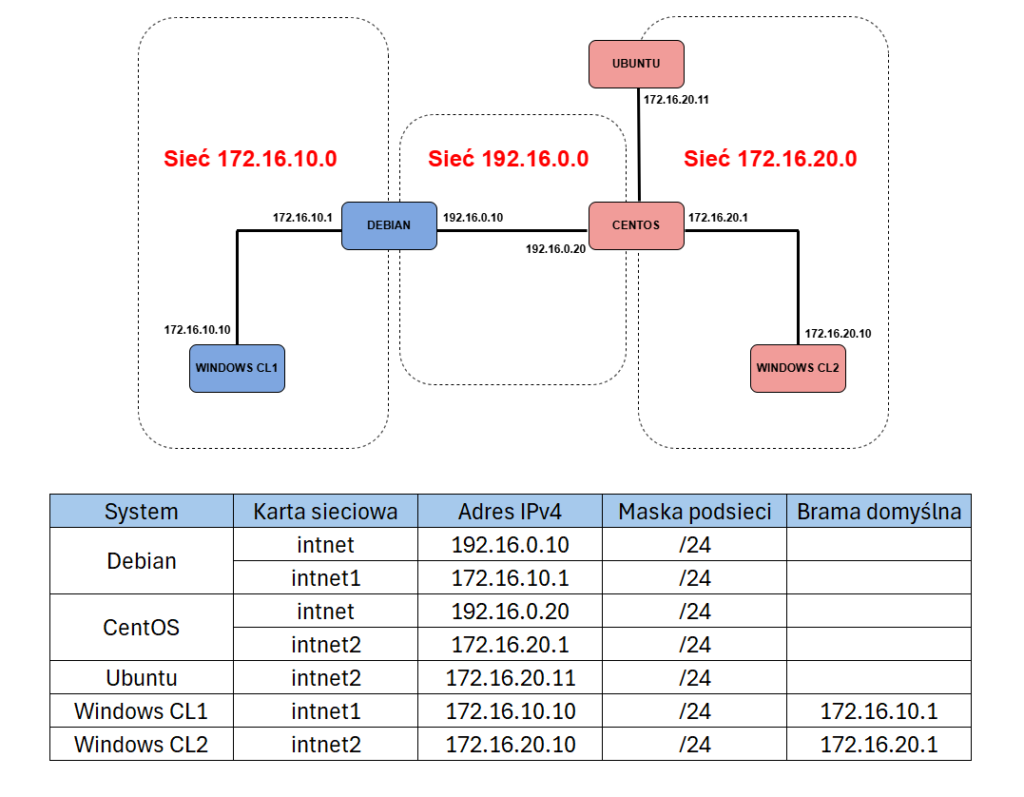
W tym artykule wykorzystam to samo środowisko laboratoryjne, które zostało zbudowane wcześniej w serii. Nie będę tu od nowa opisywał konfiguracji sieci, routingu i usług, ponieważ te elementy zostały już omówione we wcześniejszych wpisach. Zakładam, że środowisko jest gotowe i hosty potrafią się ze sobą komunikować. Skupimy się natomiast na tym, jak przeglądać, filtrować, rozdzielać i centralizować logi, wykorzystując narzędzia takie jak rsyslog, journalctl i logrotate.
Narzędzia do rejestrowania logów
Zanim przejdziemy do części praktycznej omówmy sobie kwestie teoretyczne związane z logami. W systemie Linux dostępnych jest kilka narzędzi do zarządzania i analizowania logów. Część z nich odpowiada za bieżące zbieranie komunikatów, część za ich przeglądanie, a część za porządkowanie i archiwizację.
W klasycznych systemach Linux wiele logów trafia do katalogu:
/var/logWarto jednak pamiętać, że współczesne dystrybucje często korzystają równolegle z journald, który przechowuje logi we własnym formacie binarnym i udostępnia je przez polecenie journalctl.
Syslog i Rsyslog
Syslog to klasyczny mechanizm rejestrowania logów w systemach Unix i Linux. Jego zadaniem jest przyjmowanie komunikatów od usług, procesów i jądra systemu, a następnie zapisywanie ich do odpowiednich plików.
Rsyslog to rozwinięcie klasycznego sysloga. Oferuje więcej możliwości, takich jak:
- filtrowanie komunikatów według źródła i priorytetu,
- zapisywanie logów do różnych plików,
- przesyłanie logów przez sieć,
- tworzenie własnych szablonów plików docelowych.
W systemie Debian rsyslog zwykle trzeba doinstalować ręcznie:
apt install rsyslogNajważniejszym plikiem konfiguracyjnym jest:
/etc/rsyslog.confTo właśnie tam definiuje się reguły mówiące:
- jakie logi mają być zbierane,
- z jakich usług,
- z jakim priorytetem,
- i gdzie mają zostać zapisane.
journald i journalctl
W systemach korzystających z systemd bardzo ważnym elementem obsługi logów jest journald. To usługa, która zbiera logi systemowe i przechowuje je w ustrukturyzowanej formie. Dzięki temu logi można później wygodnie filtrować po:
- usłudze,
- czasie,
- priorytecie,
- procesie,
- uruchomieniu systemu,
- oraz wielu innych polach.
Do przeglądania tych danych służy polecenie:
journalctlTo bardzo wygodne narzędzie administracyjne, bo pozwala szybko sprawdzić, co działo się z konkretną usługą, bez ręcznego przeszukiwania wielu plików w /var/log.
logrotate
Logrotate to narzędzie odpowiedzialne za rotację logów, czyli:
- zamykanie bieżących plików logów,
- tworzenie nowych,
- kompresowanie starszych,
- oraz usuwanie archiwów po określonym czasie.
Bez takiego mechanizmu logi rosłyby w nieskończoność i z czasem zaczęłyby zajmować zbyt dużo miejsca na dysku.
Główny plik konfiguracyjny logrotate to:
/etc/logrotate.confDodatkowe konfiguracje dla konkretnych usług umieszcza się zwykle w katalogu:
/etc/logrotate.dPriorytety logów
W systemie Linux logi są kategoryzowane także według poziomów ważności. Dzięki temu administrator może szybciej odróżnić zwykłe komunikaty informacyjne od sytuacji krytycznych.
Rsyslog definiuje osiem poziomów priorytetu, od najwyższego do najniższego:
- Emergency (0) – system jest bezużyteczny. To sytuacje krytyczne, które mogą oznaczać całkowitą awarię systemu.
- Alert (1) – wymagane natychmiastowe działanie. Przykład: poważne uszkodzenie usługi lub bazy danych.
- Critical (2) – obejmuje poważne błędy wpływające na stabilność systemu takie jak zatrzymanie serwera DNS, problemy sprzętowe lub przepełnienie krytycznej partycji.
- Error (3) – to typowe błędy administracyjne, na przykład nieudane uruchomienie usługi lub błędna konfiguracja.
- Warning (4) – ostrzeżenia, które mogą w przyszłości przerodzić się w poważniejszy problem, na przykład mała ilość wolnego miejsca na dysku.
- Notice (5) – zdarzenia normalne, na przykład restart usługi.
- Informational (6) – ogólne informacje o pracy systemu i usług, takie jak udane logowanie użytkownika.
- Debug (7) – bardzo szczegółowe komunikaty przydatne podczas debugowania.
Składnia pliku /etc/rsyslog.conf
Plik rsyslog.conf jest oparty na prostym mechanizmie reguł. Każda linia składa się z dwóch podstawowych części:
- selektora
- akcji
Selektor określa, jakie logi nas interesują, a akcja mówi, co z nimi zrobić.
Najczęściej selektor ma format:
FACILITY.PRIORITY- FACILITY – Określa podsystem lub usługę, z której pochodzi dane zdarzenie w logach. Przykładowo ftp, kern, cron itp.
- PRIORITY – Wskazuje na priorytet danego zdarzenia. Może przyjmować jedną z 7 wartości, które wymieniłem wcześniej. Dla przypomnienia są to: debug (7), info (6), notice (5), warning (4), err (3), crit (2), alert (1), oraz emerg (0).
To właśnie na tej podstawie możesz filtrować logi mniej lub bardziej istotne.
Znaki specjalne używane w selektorach
W regułach rsyslog można używać kilku znaków specjalnych, które ułatwiają bardziej precyzyjne filtrowanie logów.
Gwiazdka – *
Gwiazdka oznacza „wszystko” i może odnosić się zarówno do facility, jak i priority.
Na przykład:
*.* /var/log/wszystko.logoznacza: zapisuj wszystkie logi ze wszystkich źródeł.
Znak równości – =
Służy do logowania tylko jednego, konkretnego poziomu priorytetu.
Przykład:
mail.=err /var/log/mail.errTa reguła zapisuje tylko logi usługi pocztowej o priorytecie err i zapisuje je do pliku mail.err.
Wykrzyknik – !
Służy do wykluczania określonego priorytetu.
Przykład:
auth.!err /var/log/auth.logTa reguła zapisuje wszystkie logi z uwierzytelniania oprócz tych o poziomie err.
Przecinek – ,
Przecinek jest używany do grupowania logów, którym odpowiada ten sam priorytet.
Przykład:
mail,ftp.* /var/log/maillogOznacza to: zapisuj wszystkie logi z usług mail i ftp do jednego pliku.
Średnik – ;
Pozwala grupować kilka różnych selektorów w jednej linii.
Przykład:
*.=info;*.=notice /var/log/info-notice.logTaki wpis zapisze logi o priorytetach info i notice ze wszystkich usług.
Rozdzielanie logów na poszczególne pliki
Jedną z zalet rsyslog jest możliwość bardzo prostego rozdzielania logów do osobnych plików. Dzięki temu nie trzeba przeszukiwać ogromnych, wspólnych dzienników, gdy interesują nas tylko logi jednej usługi.
W naszym przykładzie rozdzielimy logi związane z usługą cron. Edytujemy plik:
/etc/rsyslog.confi dopisujemy na końcu własną regułę kierującą ważniejsze komunikaty crona od priorytetu info do warning z wykluczeniem priorytetu error, do pliku /var/log/cron-wazne.
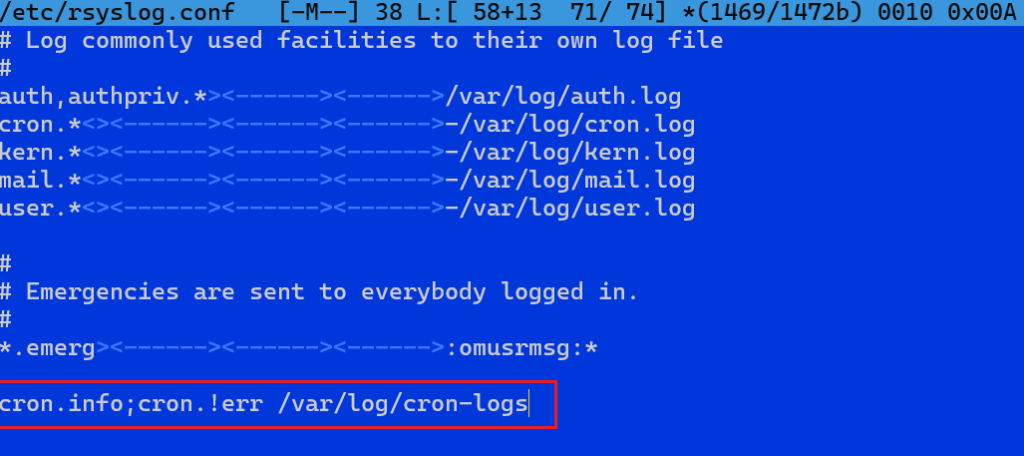
Po zapisaniu zmian restartujemy usługę:
systemctl restart rsyslogAby sprawdzić, czy konfiguracja działa, możemy wygenerować zdarzenie związane z usługą cron, na przykład przez jej restart:
systemctl restart cronJeśli wszystko zostało ustawione poprawnie, w katalogu /var/log powinien pojawić się odpowiedni plik z logami crona.

Rotowanie logów za pomocą narzędzia logrotate
Samo gromadzenie logów nie wystarczy. Z czasem pliki dziennika mogą stać się bardzo duże, dlatego trzeba zadbać o ich rotację.
W tym celu utworzymy własny plik konfiguracyjny dla logrotate
touch /etc/logrotate.d/cronPlik ten będzie zawierał konfigurację rotowania logów z utworzonego wcześniej pliku cron-logs. Wklejamy do niego odpowiednią konfigurację.
/var/log/cron-logs {
daily
create 0664 root root
rotate 20
compress
}Należy jeszcze nadać odpowiednie uprawnienia dla pliku
chmod 644 /etc/logrotate.d/cron
chown root:root /etc/logrotate.d/cronCo oznaczają te opcje?
- daily – log będzie rotowany codziennie
- create 0664 root root – po rotacji zostanie utworzony nowy plik logu z uprawnieniami
0664, właścicielemrooti grupąroot - rotate 20 – system zachowa maksymalnie 20 poprzednich archiwów logu
- compress – starsze logi będą kompresowane, zwykle do plików
.gz
W praktyce oznacza to, że plik cron-logs będzie codziennie zamykany, a jego starsze wersje będą przechowywane w formie archiwów. Dzięki temu bieżący log pozostanie czytelny i niewielki, a starsze wpisy nadal będzie można odtworzyć w razie potrzeby.
Normalnie trzeba byłoby poczekać do kolejnego dnia, żeby sprawdzić działanie tej konfiguracji, ale logrotate pozwala wymusić rotację ręcznie:
logrotate -vf /etc/logrotate.d/cronJeśli wykonasz to polecenie kilka razy, powinieneś zobaczyć w katalogu /var/log kolejne zrotowane i skompresowane wersje pliku cron-logs.
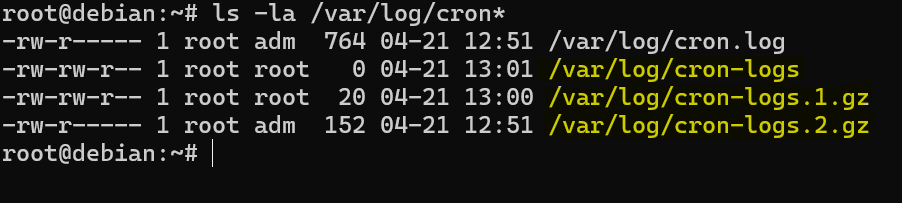
To bardzo wygodne, bo pozwala od razu sprawdzić, czy konfiguracja rotacji działa poprawnie, bez czekania na upływ czasu.
Konfiguracja kolektora logów z wykorzystaniem rsyslog
Jedną z bardzo praktycznych funkcji rsyslog jest możliwość centralizacji logów. Dzięki temu logi z kilku systemów mogą trafiać do jednego miejsca. To wygodne w większych środowiskach, ale bardzo dobrze sprawdza się też w domowym labie, bo pozwala przećwiczyć architekturę podobną do tej spotykanej w prawdziwych sieciach.
W naszym środowisku:
- Debian będzie pełnił rolę centralnego kolektora logów
- CentOS i Ubuntu będą wysyłały do niego zdarzenia
Konfiguracja kolektora na Debianie
Na Debianie, który będzie odbierał logi, edytujemy plik:
/etc/rsyslog.confi odkomentowujemy linie odpowiedzialne za odbieranie logów po sieci.

Dodatkowo tworzymy nowy szablon, który będzie używany do odbierania zdalnie logów z serwera CentOS.
$template FromIp,"/var/log/%FROMHOST-IP%.log"
*.* ?FromIp
& ~Dzięki temu logi z poszczególnych systemów nie będą mieszały się w jednym pliku, tylko zostaną zapisane osobno według adresu IP nadawcy.
Po zapisaniu zmian restartujemy usługę:
systemctl restart rsyslogKonfiguracja klientów – CentOS i Ubuntu
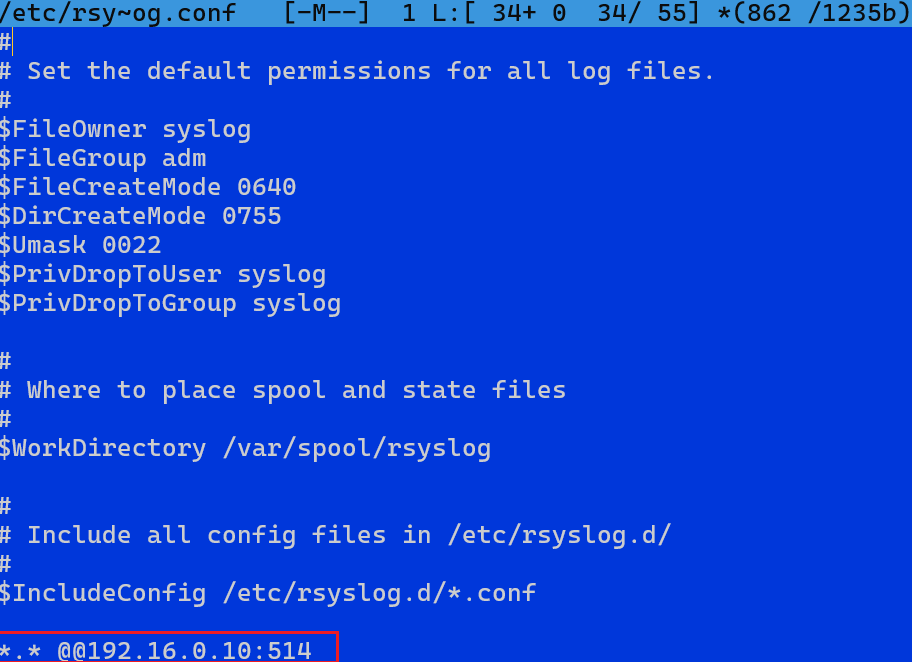
Na systemie CentOS, który będzie wysyłać logi do Debiana, edytujemy plik /etc/rsyslog.conf i dopisujemy w nim linię:
*.* @@172.16.10.1:514Podwójny znak @@ oznacza wysyłanie logów po TCP.
Jeśli użyłbyś pojedynczego @, logi byłyby wysyłane po UDP.
To samo możesz zrobić także na Ubuntu, jeśli chcesz, aby również ten host przesyłał swoje zdarzenia do Debiana.
Po zapisaniu konfiguracji restartujemy usługę:
systemctl restart rsyslogTest wysyłania logów
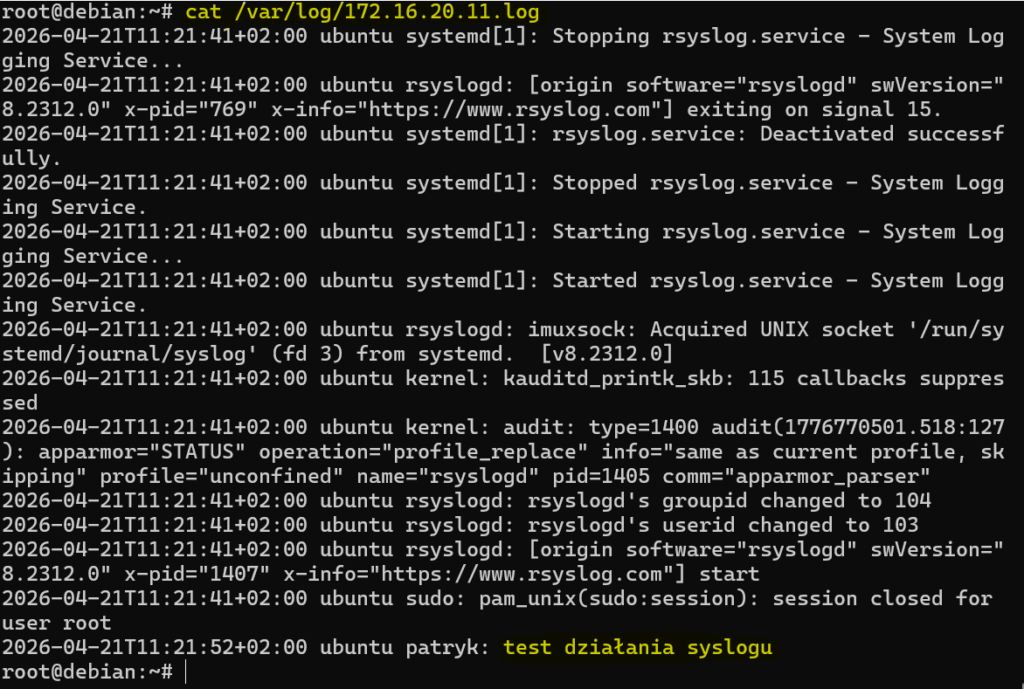
Aby wygenerować testowy wpis, możemy użyć polecenia:
logger "test działania syslogu"Jeśli wszystko działa poprawnie, na Debianie w katalogu /var/log powinien pojawić się plik związany z adresem IP nadawcy, a w nim zapisany również nasz testowy komunikat.
Wykorzystanie narzędzia journald do obsługi logów
Obok klasycznych plików logów bardzo ważnym źródłem informacji w nowoczesnych systemach Linux jest journald. To właśnie tam trafia wiele logów usług uruchamianych przez systemd.
Podstawowym poleceniem używanym do wyświetlania dzienników jest:
journalctlDomyślne wywołanie pokaże cały dostępny dziennik od najstarszego zdarzenia do najnowszego. Przy dużej liczbie wpisów nie zawsze jest to wygodne, dlatego warto znać kilka praktycznych filtrów.
Logi od najnowszych
Aby wyświetlić logi od najnowszych do najstarszych:
journalctl -rOstatnie wpisy
Aby ograniczyć liczbę wyświetlanych logów:
journalctl -n 20To bardzo przydatne, gdy chcesz zobaczyć tylko końcówkę dziennika.
Filtrowanie po czasie
Możesz ograniczyć logi do określonego czasu, na przykład:
journalctl --since "25 minutes ago"To bardzo wygodne przy diagnozowaniu świeżego problemu.
Filtrowanie po usłudze
Jedną z najpraktyczniejszych funkcji journalctl jest możliwość ograniczenia logów do konkretnej usługi.
journalctl -u networking
journalctl _COMM=cron
journalctl -u sshd -fDzięki temu możesz łatwo sprawdzić:
- logi usługi sieciowej,
- logi crona,
- albo śledzić na żywo logi sshd
W naszym środowisku bardzo przydatne byłyby też polecenia filtrujące logi z usług, które konfigurowaliśmy.
journalctl -u bind9
journalctl -u isc-dhcp-server
journalctl -u sshTryb śledzenia logów
Dodanie przełącznika -f działa podobnie do tail -f i pozwala śledzić nowe wpisy na bieżąco.
journalctl -u sshd -fTo bardzo przydatne podczas testowania połączeń i restartów usług.
Szczegółowy widok wpisu
Jeśli chcesz zobaczyć pełną strukturę logu, możesz użyć formatu verbose.
journalctl -o verbose -n 1To pokaże wszystkie pola danego wpisu, co bywa bardzo pomocne podczas dokładniejszej analizy.
Logi z konkretnego uruchomienia systemu
Journald pozwala też przeglądać logi z poszczególnych startów systemu:
journalctl --list-boots
journalctl -b -0To przydaje się wtedy, gdy chcesz sprawdzić, co działo się od ostatniego restartu.
Filtrowanie po priorytecie
Możesz też ograniczyć logi do określonego poziomu ważności, na przykład tylko do błędów:
journalctl -p errTo pozwala pominąć mniej istotne wpisy i szybciej znaleźć realny problem.
Zarządzanie miejscem zajmowanym przez journald
Dziennik systemd też z czasem potrafi urosnąć. Warto więc znać podstawowe polecenia do zarządzania jego rozmiarem.
Sprawdzenie zajętości:
journalctl --disk-usageUsunięcie starych logów tak, aby dziennik zajmował maksymalnie 1 GB:
journalctl --vacuum-size=1GUsunięcie logów starszych niż rok:
journalctl --vacuum-time=1yearsTo przydatne zwłaszcza na serwerach i maszynach testowych, gdzie logi potrafią gromadzić się przez długi czas.
Podsumowanie
Logi to jeden z najważniejszych elementów codziennej administracji Linuxem. To właśnie one pozwalają zrozumieć, co naprawdę dzieje się w systemie, gdy usługa nie działa tak, jak powinna. Dzięki nim można nie tylko diagnozować błędy, ale też lepiej monitorować stan usług, porządkować zdarzenia i centralizować informacje z wielu hostów.