
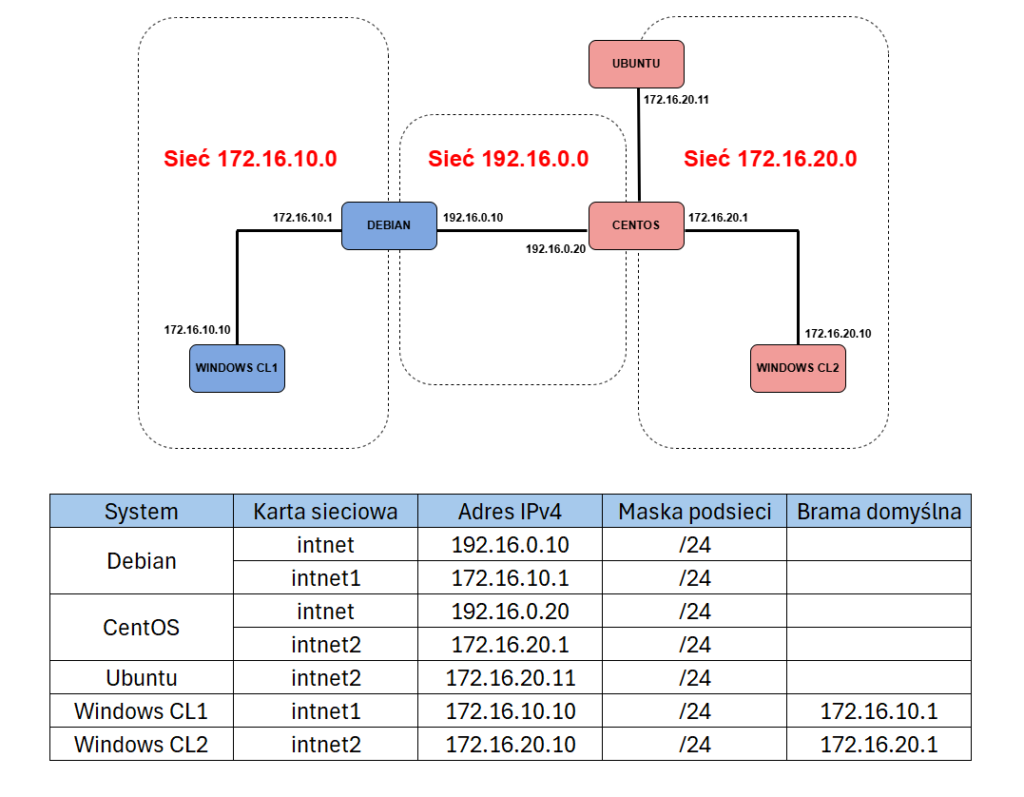
Konfiguracja usług sieciowych w Linuxie to dopiero połowa pracy. Sama wiedza o tym, jak ustawić adres IP, routing czy serwer DNS, nie wystarczy, jeśli w pewnym momencie coś przestanie działać i nie będziesz wiedział, gdzie leży problem. A w praktyce takie sytuacje pojawiają się bardzo często. Klient nie rozwiązuje nazwy hosta, serwer DNS odpowiada tylko lokalnie, pakiety dochodzą do routera, ale nie wracają z drugiej strony, a nowy rekord istnieje na masterze, ale wciąż nie pojawia się na slave.
W takich momentach nie wystarczy już samo ping i szybkie spojrzenie w plik konfiguracyjny. Trzeba umieć sprawdzić, czy klient naprawdę wysłał zapytanie, czy serwer DNS je odebrał, jaką odpowiedź zwrócił i czy pakiet w ogóle przeszedł przez sieć. Do tego służą właśnie narzędzia diagnostyczne. W Linuxie i Windowsie bardzo często wykorzystuje się do tego nslookup, dig oraz tcpdump. Każde z nich działa trochę inaczej, każde pokazuje inny poziom problemu i każde przydaje się w trochę innym momencie.
W tym artykule pokażę Ci, jak diagnozować problemy z DNS i siecią w Linuxie, wykorzystując dokładnie to samo środowisko, które budowaliśmy wcześniej.
Przejdziemy przez podstawowe zastosowania nslookup, dig i tcpdump, omówimy najważniejsze różnice między nimi, a potem wykonamy serię praktycznych testów i awarii: od prostych problemów z rekordami DNS, przez brak odpowiedzi z serwera slave, aż po problemy z forwardingiem i zaporą sieciową. Zademonstruję Ci problemy na jakie natrafiłem w poprzednim artykule i narzędzia, które pomogły mi je rozwiązać.
Dlaczego samo ping nie wystarcza?
Zacznijmy od prostej sytuacji, która bardzo dobrze pokazuje, dlaczego samo ping nie wystarcza. Na Windowsie CL1 wykonujemy dwa testy:
ping 172.16.10.1
ping 172.16.20.11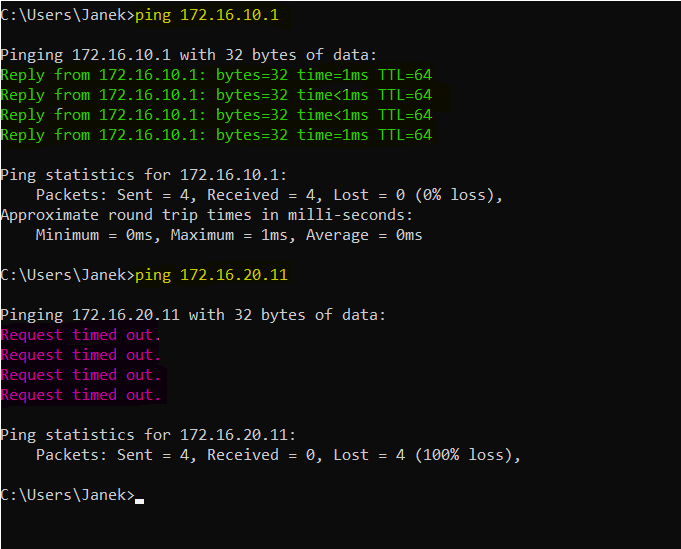
Pierwszy ping do Debiana działa. Drugi, skierowany do Ubuntu, już nie. Na pierwszy rzut oka wygląda to jak zwykły problem z siecią, ale tak naprawdę ten objaw może oznaczać kilka różnych rzeczy naraz:
- brak poprawnej trasy,
- brak forwardingu na routerze,
- zablokowany ruch ICMP po drodze,
- problem z odpowiedzią hosta docelowego,
- albo lokalną zaporę na którymś z systemów.
I właśnie tutaj zaczyna się różnica między „sprawdzaniem czy działa” a prawdziwą diagnostyką. Jeśli coś nie działa, ping nie powie Ci jeszcze, na którym etapie wszystko się zatrzymało. Właśnie dlatego przy diagnostyce warto rozdzielić problem na warstwy i używać narzędzi, które pokazują konkretny fragment całego procesu.
nslookup – szybki test działania DNS
To bardzo dobre narzędzie do pierwszego kontaktu z problemem. Nie daje tak szczegółowego obrazu jak dig, ale pozwala w kilka sekund sprawdzić, czy serwer DNS odpowiada i czy zna konkretny rekord. To często wystarcza, żeby ustalić, czy problem jest ogólny, czy dotyczy tylko jednego hosta albo jednego typu rekordu.
Podstawowe użycie nslookup
Najprostszy przykład wygląda tak:
nslookup dns1.firma.local 172.16.10.1W tym przypadku pytasz konkretnie serwer DNS Debian o rekord dns1.firma.local.
Możesz wykonać to samo pytanie do serwera slave na Ubuntu:
nslookup dns1.firma.local 172.16.20.11To bardzo wygodny sposób na szybkie porównanie odpowiedzi z:
- serwera master
- oraz serwera slave
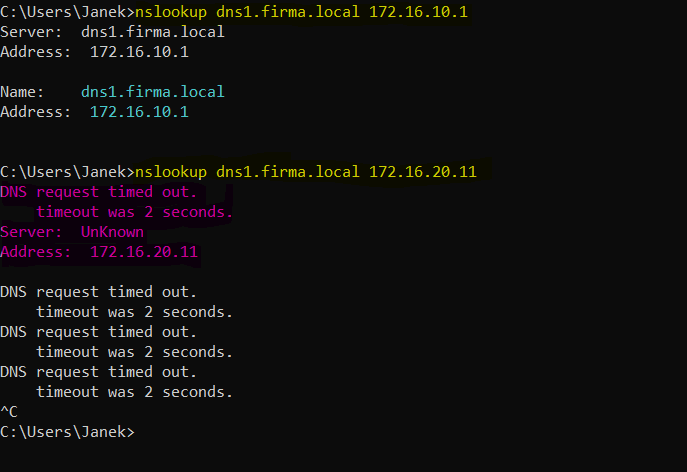
Jeśli oba zwracają ten sam rekord, to znaczy, że synchronizacja strefy działa poprawnie. Jeśli jeden odpowiada, a drugi nie, to od razu wiadomo, w którą stronę iść z diagnostyką.
W tym przypadku widzimy, że serwer master odpowiada, a serwer slave nie odpowiada. I tu zaczynają się schodki bo po drodze do serwera Ubuntu jest kilka urządzeń i na pierwszy rzut oka nie wiadomo gdzie leży wina. Pokaże jak podejść do tego tematu w momencie gdy przedstawię wszystkie narzędzia.
nslookup dla reverse DNS
To samo narzędzie można wykorzystać do sprawdzenia rekordów PTR, czyli reverse DNS.
nslookup 172.16.10.10 172.16.10.1Jeśli strefa odwrotna jest skonfigurowana poprawnie, powinieneś otrzymać nazwę hosta przypisaną do tego adresu, w tym przypadku cl1.firma.local.

To bardzo dobry test do sprawdzenia, czy działa nie tylko zwykłe mapowanie nazwy na IP, ale też odwrotne mapowanie adresu na nazwę.
Interaktywny tryb nslookup
nslookup może działać także w trybie interaktywnym. To przydatne, gdy chcesz zadawać kilka pytań do jednego serwera bez wpisywania jego adresu za każdym razem. To bardzo wygodne przy szybkich testach po stronie klienta.
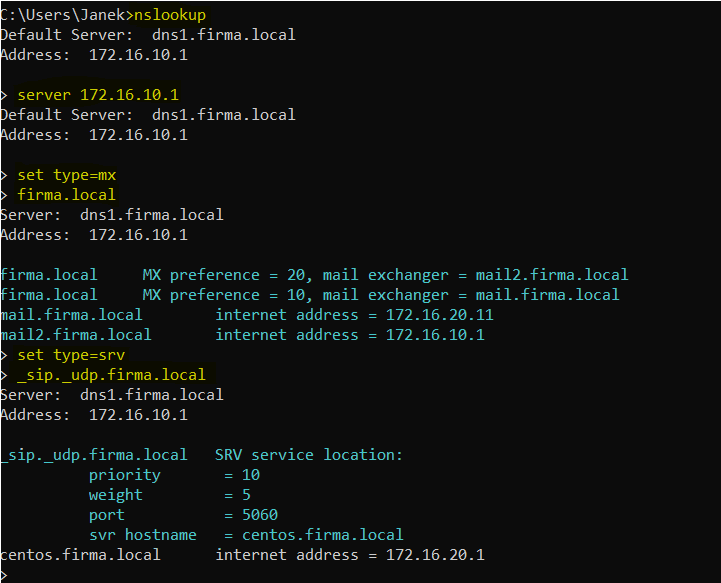
nslookup
server 172.16.20.11
set type=mx
firma.locaLW ten sposób możesz zapytać o:
- rekordy MX,
- rekordy SRV,
- rekordy PTR,
- albo po prostu przełączać się między różnymi serwerami DNS.
dig – dokładna analiza odpowiedzi DNS
Jeśli nslookup jest dobry na szybki test, to dig jest narzędziem do dokładnego zrozumienia odpowiedzi DNS. W praktyce bardzo często dopiero dig pokazuje, czy rekord rzeczywiście istnieje, z której strefy pochodzi odpowiedź, jaki jest numer seryjny strefy i czy serwer zwraca wynik poprawnie.
Podstawowe zapytanie dig
Poniżej prezentuje przykładowe zapytanie do serwera master.
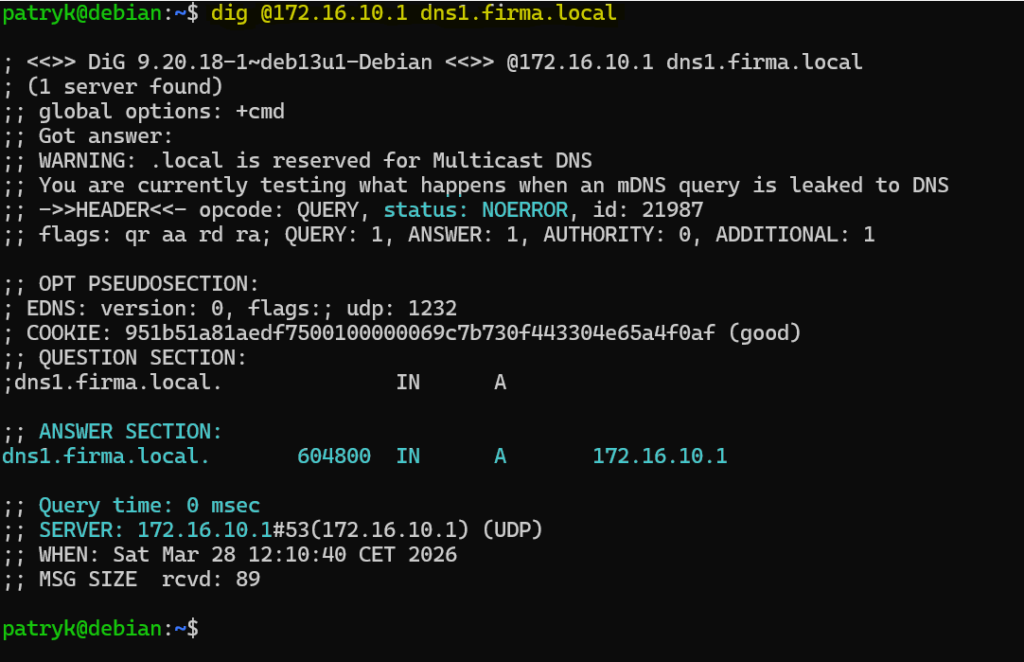
dig @172.16.10.1 dns1.firma.localNajpierw wskazujemy adres IP serwera DNS, z którego ma przyjść odpowiedź a następnie pytamy o rekord. Jak widać na poniższym screenie w wyniku zapytania otrzymaliśmy adres IP rekordu dns1.firma.local.
Wynik dig jest dużo bogatszy niż wynik nslookup. Warto zwrócić uwagę przede wszystkim na:
- status
- ANSWER SECTION
- Query time
- SERVER
Spróbujmy odpytać serwer slave w ten sposób. Niestety w tym przypadku dostajemy komunikat “host unreachable”. Z niewiadomego powodu na ten moment nie jest dostępny. W dalszej części artykułu pokaże jak naprawić ten problem.

Co oznaczają najczęstsze statusy?
W odpowiedzi dig bardzo dużo mówi sam status zwrócony przez serwer DNS. To właśnie on często jako pierwszy podpowiada, z jakim typem problemu masz do czynienia.
NOERROR oznacza, że serwer obsłużył zapytanie poprawnie. Nie zawsze musi to od razu znaczyć, że rekord został znaleziony, ale pokazuje, że samo zapytanie nie zakończyło się błędem.
NXDOMAIN oznacza, że taka nazwa nie istnieje w danej strefie. Najczęściej wskazuje to na literówkę, brak rekordu albo pytanie skierowane do niewłaściwej strefy DNS.
SERVFAIL oznacza, że serwer próbował odpowiedzieć, ale coś poszło nie tak po drodze. W praktyce bardzo często sugeruje problem z forwardingiem, odpowiedzią z innego serwera DNS, walidacją DNSSEC albo ogólnym błędem po stronie samej usługi DNS.
REFUSED oznacza, że serwer świadomie odmawia odpowiedzi. Taki status zwykle pojawia się wtedy, gdy rekursja jest wyłączona, obowiązują ograniczenia allow-query albo serwer został skonfigurowany tak, by nie odpowiadać na zapytania z danego źródła.
dig dla różnych typów rekordów
To samo narzędzie możesz wykorzystać do sprawdzania różnych typów rekordów.
- Rekordy A – dig @172.16.10.1 sklep.firma.local
- Rekordy MX – dig @172.16.10.1 firma.local MX
- Rekordy SRV – dig @172.16.10.1 _sip._udp.firma.local SRV
- Reverse DNS – dig @172.16.10.1 -x 172.16.10.10
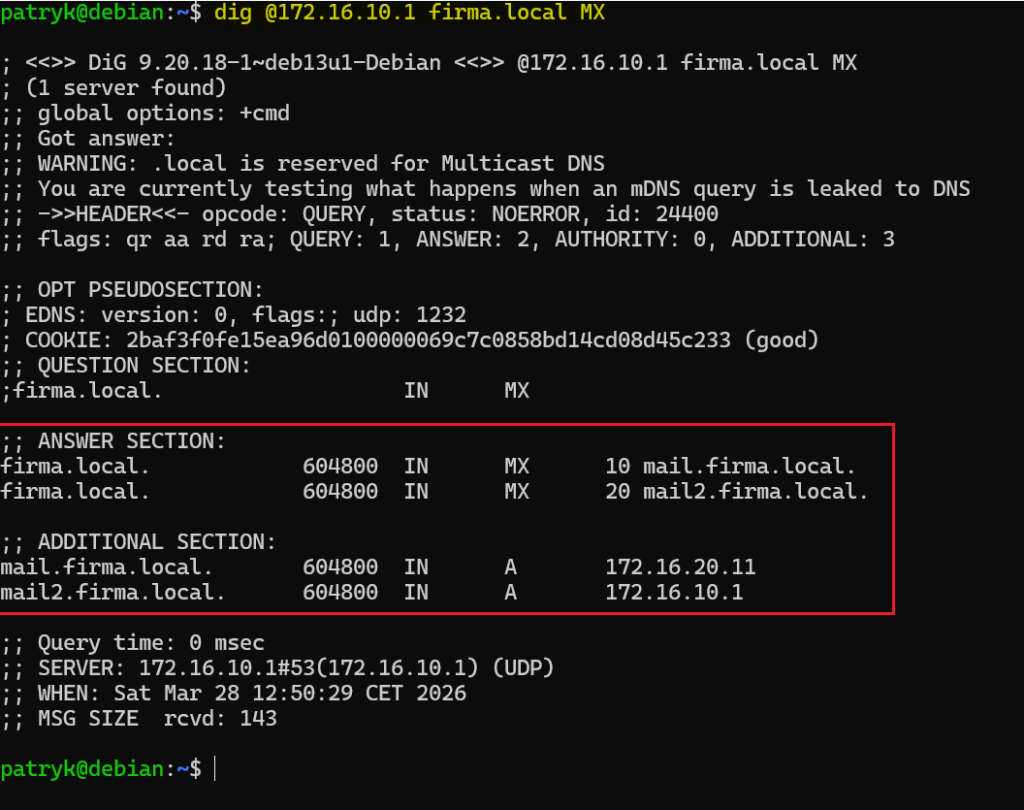
To bardzo wygodne, bo jednym narzędziem możesz sprawdzić praktycznie cały przekrój informacji DNS.
dig i numer seryjny SOA
Jedno z najlepszych zastosowań dig w środowisku z master/slave to sprawdzanie numeru seryjnego strefy:
dig @172.16.10.1 firma.local SOA
dig @172.16.20.11 firma.local SOATo pozwala bardzo szybko ustalić:
- czy slave pobrał już nową wersję strefy,
- czy nadal trzyma starszą kopię,
- czy problemem jest brak zwiększenia numeru seryjnego.
Przydatne opcje dig
+short – Pokazuje tylko sam wynik bez całej reszty:
dig @172.16.20.11 sklep.firma.local +short+tcp – Wymusza użycie TCP zamiast UDP:
dig @172.16.20.11 dns1.firma.local +tcpTo bardzo przydatne, gdy podejrzewasz problem z odpowiedziami po UDP.
tcpdump – podgląd rzeczywistego ruchu
To narzędzie pokazuje, co naprawdę idzie po sieci. Jest bezcenne wtedy, gdy chcesz sprawdzić, czy klient na pewno wysłał zapytanie, czy serwer je odebrał i czy odpowiedź wróciła. Podgląd obserwujesz na bieżąco, informacje wyskakują na ekranie.
Podgląd ruchu DNS
Na Debianie możesz podejrzeć cały ruch DNS tak:
tcpdump -ni any port 53Jeżeli chcesz zawęzić widok tylko do konkretnego klienta, na przykład CL2, możesz użyć:
sudo tcpdump -ni any host 172.16.20.10 and port 53To pozwala bardzo szybko sprawdzić:
- czy klient naprawdę wysyła pytania,
- czy serwer je dostaje,
- i czy pojawia się odpowiedź.
Podgląd ICMP
Do diagnostyki pingów i routingu świetnie nadaje się:
sudo tcpdump -ni any icmpDlaczego tcpdump jest tak przydatny
To narzędzie pozwala rozstrzygnąć rzeczy, których nie pokaże sam ping ani dig. Na przykład:
- klient mówi, że DNS timeoutuje,
- ale tcpdump pokazuje, że pytanie w ogóle nie wyszło,
- albo pytanie dochodzi do serwera, ale odpowiedź jest blokowana przez nftables,
- albo routing działa tylko w jedną stronę.
I właśnie dlatego tcpdump tak dobrze uzupełnia nslookup i dig.
Troubleshooting krok po kroku – przykłady wykorzystania narzędzi
Najlepszy sposób nauki diagnostyki to nie tylko patrzenie na działające środowisko, ale też przejście przez kilka prawdziwych awarii. W moim przypadku punkt wyjścia był prosty: z CL1 można było pingować Debiana, ale Ubuntu już nie odpowiadało. Taki objaw wygląda niewinnie, ale po rozłożeniu go na etapy okazało się, że po drodze kryły się różne problemy.
Problem 1 – sprawdzamy, czy Debian w ogóle forwarduje ruch
Skoro CL1 widzi Debiana, ale nie widzi Ubuntu, pierwszym podejrzanym staje się router po drodze. W naszym labie rolę hosta pośredniczącego pełnił właśnie Debian, więc naturalnym krokiem było sprawdzenie, czy pakiet w ogóle do niego dochodzi i czy jest przekazywany dalej.
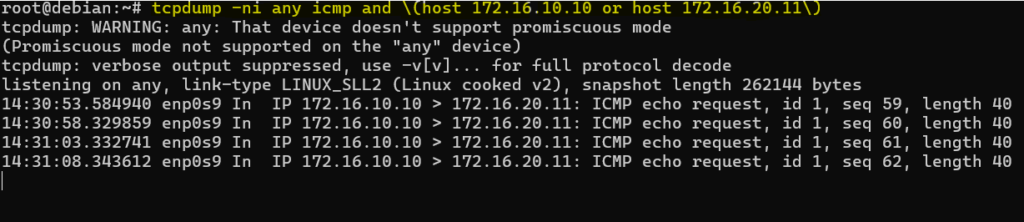
Na Debianie uruchomiłem:
tcpdump -ni any icmp and \(host 172.16.10.10 or host 172.16.20.11\)Następnie z CL1 ponowiłem:
ping 172.16.20.11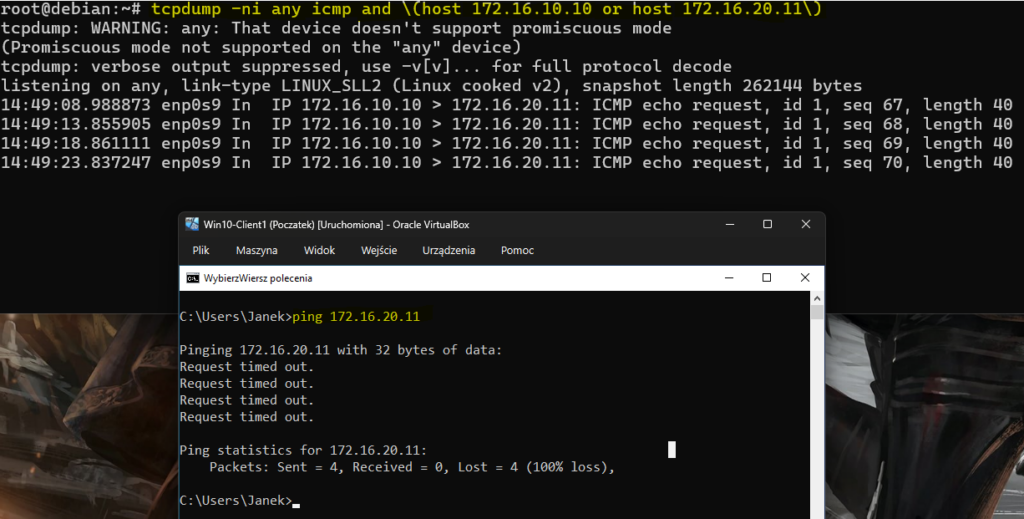
Wynik był bardzo czytelny: pakiet od 172.16.10.10 dochodził do Debiana, ale nie pojawiał się po stronie interfejsu prowadzącego dalej do CentOS-a i Ubuntu. To oznaczało, że problem nie leżał jeszcze w Ubuntu, tylko wcześniej – Debian nie forwardował ruchu.
Co było popsute i jak to naprawiłem?

Na Debianie problemem był wyłączony IP forwarding albo błędna polityka przekazywania pakietów pomiędzy interfejsami. Za pomocą polecenia sysctl -p sprawdziłem czy routing jest włączony. Jako, że nie był, to włączyłem go na stałe poleceniem:
sysctl -w net.ipv4.ip_forward=1Problem 2 – przechodzimy do DNS i okazuje się, że Ubuntu odpowiada tylko lokalnie
Skoro sieć zaczęła działać poprawnie po IP, można było przejść do diagnostyki samego DNS. I tu pojawił się kolejny problem: CL1 nie potrafił rozwiązywać nazw z Ubuntu slave, mimo że Ubuntu było osiągalne już po IP.
Na kliencie wykonałem poniższe polecenie i dostałem timeout.:
nslookup dns1.firma.local 172.16.20.11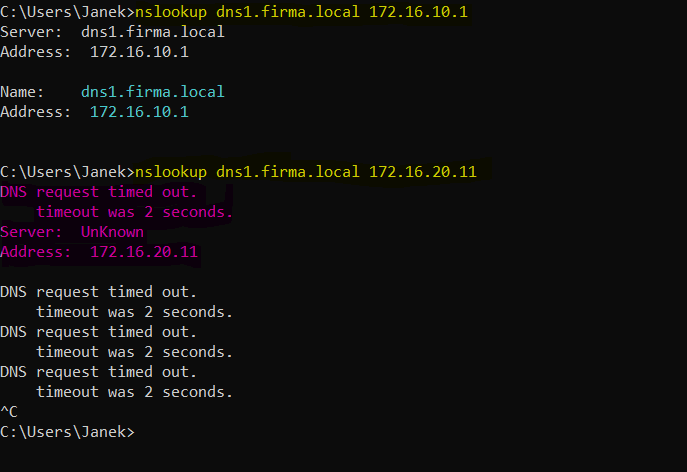
Na pierwszy rzut oka wyglądało to jak problem z samym serwerem DNS. Ale to właśnie tutaj dobrze widać różnicę między nslookup, dig i tcpdump.
Co pokazał dig?
Na samym Ubuntu wykonałem:
dig @172.16.20.11 dns1.firma.locali dostałem poprawną odpowiedź. To oznaczało, że:
- strefa jest załadowana,
- rekord istnieje,
- named działa lokalnie.
Czyli problem nie leżał w samym rekordzie ani w konfiguracji strefy.

Co pokazał tcpdump?
Na Ubuntu uruchomiłem:
sudo tcpdump -ni any host 172.16.20.10 and port 53Następnie ponowiłem nslookup z CL1. Wynik był bardzo ciekawy. W tcpdump było widać, że zapytania od klienta dochodzą do Ubuntu, ale odpowiedzi nie wracają do sieci. To oznaczało, że serwer dostaje pytania, ale coś blokuje odpowiedź.
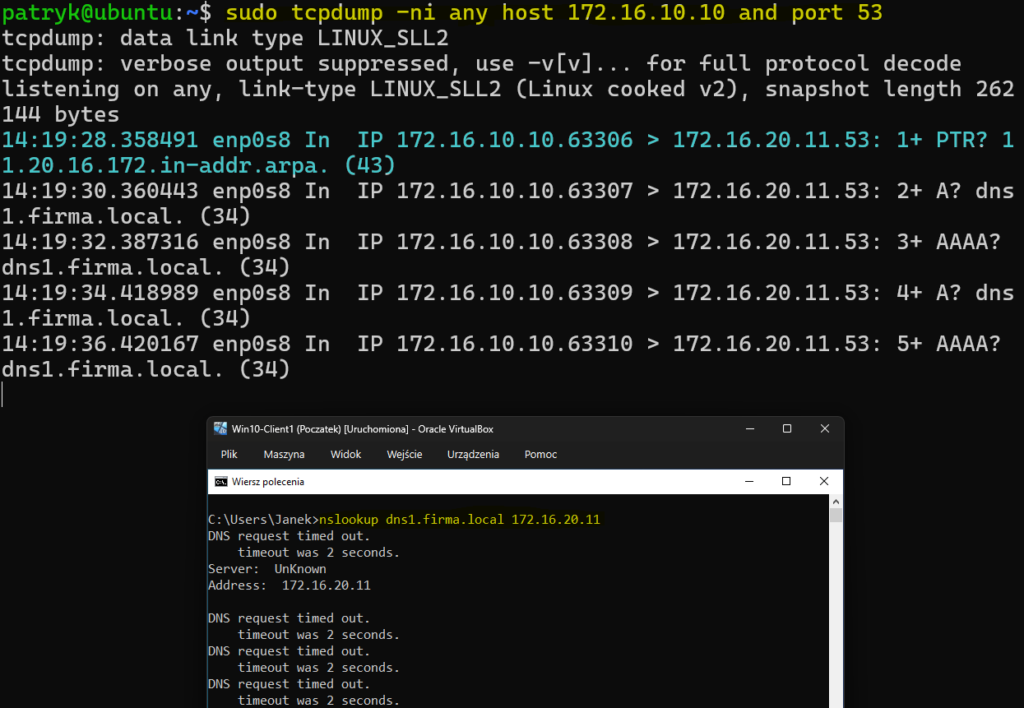
Co było popsute i jak to naprawiłem?
Winne okazało się aktywne nftables na Ubuntu. To był dokładnie ten typ problemu, którego nie widać od razu po samym ping ani po samym dig. Lokalnie wszystko wyglądało dobrze, ale ruch wychodzący był filtrowany.
Na Ubuntu wykonałem:
sudo nft flush rulesetPo tej operacji serwer slave od razu zaczął odpowiadać klientom w sieci, a nslookup z CL2 zaczął działać poprawnie.
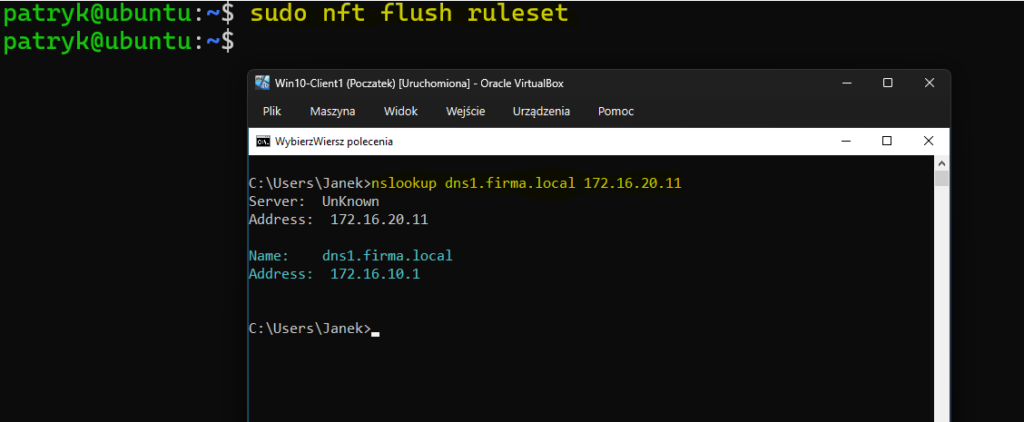
Problem 3 – nowy rekord istnieje na masterze, ale nie ma go na slave
To jeden z tych problemów, które na początku wyglądają groźnie, a w praktyce bardzo często wynikają z jednego drobnego przeoczenia. W naszym labie sytuacja wyglądała tak: na Debianie jako serwerze master dodałem nowy rekord do strefy firma.local, ale na Ubuntu jako serwerze slave rekord wciąż nie był widoczny. Na pierwszy rzut oka można było pomyśleć, że coś zepsuło się w samym transferze strefy. W rzeczywistości problem był dużo prostszy — po edycji pliku strefy nie został zwiększony numer seryjny w rekordzie SOA.
To bardzo ważny szczegół, bo właśnie numer seryjny mówi serwerowi podrzędnemu, czy na masterze pojawiła się nowa wersja strefy. Jeśli serial się nie zmienia, to z punktu widzenia slave’a nic nowego się nie wydarzyło. Nawet jeśli w pliku na Debianie rzeczywiście pojawił się nowy rekord, Ubuntu nadal będzie uważało, że ma aktualną kopię danych i nie będzie miało powodu, żeby pobierać strefę jeszcze raz.
Co celowo zepsułem?
Na Debianie dodałem nowy rekord do pliku strefy, na przykład:
blog IN A 172.16.10.1ale zostawiłem stary numer seryjny w rekordzie SOA. Następnie zrestartowałem usługę DNS na masterze i sprawdziłem rekord na obu serwerach.
Jak wyglądał objaw?
Na masterze rekord już działał:
dig @172.16.10.1 www.firma.localale na slave nadal go nie było:
dig @172.16.20.11 www.firma.localW praktyce bardzo często taki test na Ubuntu kończy się odpowiedzią NXDOMAIN, czyli informacją, że taka nazwa nie istnieje. I właśnie to jest moment, w którym łatwo błędnie założyć, że zepsuł się transfer strefy.
Jak to sprawdzić poprawnie?
W takiej sytuacji dig jest idealnym narzędziem diagnostycznym. Zamiast od razu szukać problemu w logach albo restartować usługi, najlepiej porównać rekord SOA na obu serwerach:
dig @172.16.10.1 firma.local SOA
dig @172.16.20.11 firma.local SOANajważniejszą rzeczą w wyniku jest numer seryjny strefy. Jeśli Ubuntu pokazuje starszy numer niż Debian to znaczy, że serwer slave nie pobrał nowej wersji strefy.
To bardzo ważny moment diagnostyczny, bo pokazuje, że problem nie musi leżeć w samym mechanizmie transferu strefy. Czasem slave działa poprawnie, tylko po prostu nie dostał sygnału, że ma pobrać nowszą wersję danych.
Jak naprawiłem problem?
Naprawa polegała na zwiększeniu numeru seryjnego w rekordzie SOA na Debianie. Po zapisaniu pliku i restarcie usługi DNS master mógł już poinformować slave’a, że strefa została zmieniona.
Dopiero po tej zmianie Ubuntu mogło pobrać nową wersję danych i zacząć odpowiadać z uwzględnieniem nowego rekordu.
Jak łączyć nslookup, dig i tcpdump w praktyce
Po przejściu przez te trzy problemy bardzo dobrze widać, że każde z tych narzędzi ma trochę inną rolę.
nslookup najlepiej sprawdza się wtedy, gdy chcesz szybko zobaczyć sytuację z punktu widzenia klienta. To dobre narzędzie na start, bo od razu pokazuje, czy serwer odpowiada i czy klient coś dostaje.
dig przydaje się wtedy, gdy chcesz zrozumieć odpowiedź dokładniej. Dzięki niemu możesz ustalić, czy rekord istnieje, czy odpowiedź pochodzi z właściwej strefy, jaki jest status zapytania i czy slave ma już aktualną wersję danych.
tcpdump jest niezastąpiony wtedy, gdy trzeba rozstrzygnąć, czy pakiet w ogóle przeszedł przez sieć. To właśnie dzięki niemu da się stwierdzić:
- czy klient naprawdę wysłał pytanie,
- czy router przekazał ruch dalej,
- czy serwer dostał zapytanie,
- i czy odpowiedź została wysłana z powrotem.
W praktyce najlepszy efekt daje właśnie połączenie tych trzech narzędzi. Jedno pokazuje objaw, drugie dokładnie opisuje odpowiedź, a trzecie udowadnia, co faktycznie wydarzyło się na poziomie ruchu sieciowego.