
Samo ustawienie adresu IP to dopiero połowa sukcesu. Komputer musi jeszcze wiedzieć, jak tłumaczyć nazwy na adresy IP i odwrotnie. Bo jasne, da się pracować, wpisując wszędzie same adresy, ale to trochę jak zapamiętywanie numerów telefonów wszystkich znajomych – technicznie możliwe, praktycznie mało wygodne.
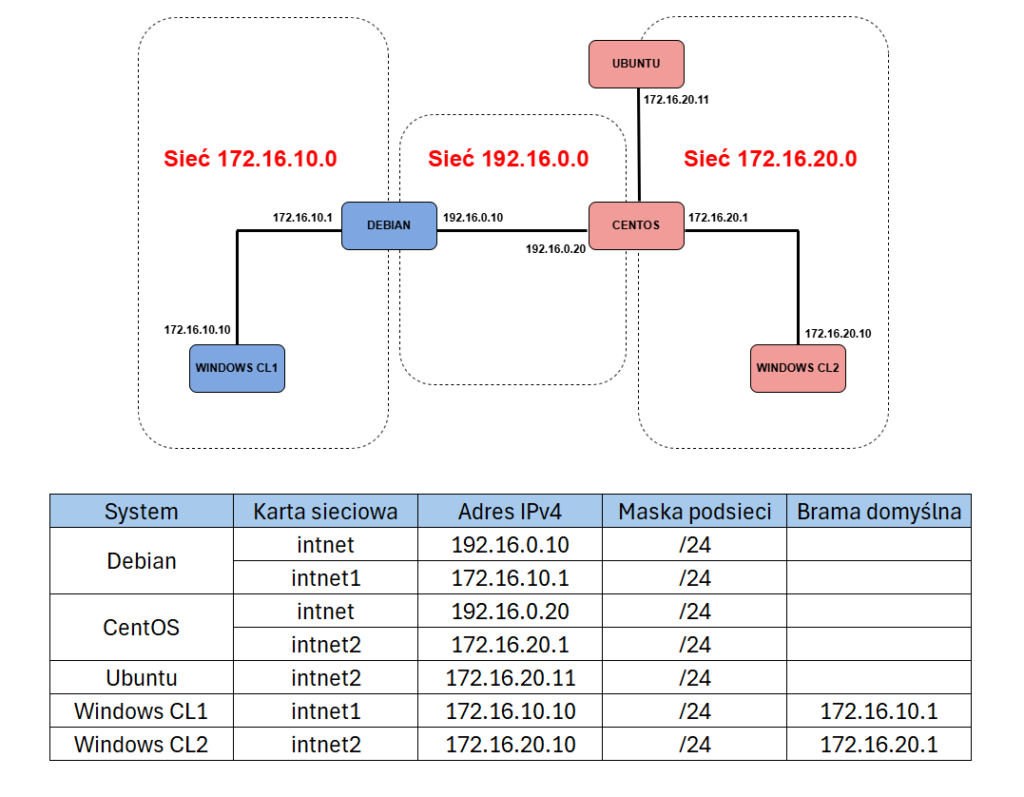
Ten artykuł jest bezpośrednią kontynuacją poprzedniego wpisu o konfiguracji sieci. Zakładam więc, że w Twoim laboratorium wszystkie maszyny mają już poprawnie ustawione interfejsy, adresy IP i bramy zgodnie z topologią. To ważne, bo nazwy hostów i DNS mają sens dopiero wtedy, gdy systemy są już prawidłowo osadzone w swojej sieci. W kolejnym kroku, czyli w trzecim artykule, wykorzystamy tę samą konfigurację do uruchomienia routingu pomiędzy podsieciami.
Zmiana nazwy hosta w Linuxie
Hostname to po prostu nazwa Twojej maszyny w systemie. Widzisz ją m.in. w promptcie terminala, w logach, w komunikatach systemowych, a często też wykorzystują ją usługi sieciowe (np. przy identyfikacji hosta w sieci). To niby drobiazg, ale dobrze ustawiony hostname bardzo ułatwia życie. Zwłaszcza wtedy, gdy masz więcej niż jedną maszynę i nie chcesz zgadywać, czy właśnie jesteś na server1, server2, czy na tej trzeciej, gdzie lepiej niczego nie dotykać.
Jak sprawdzić aktualny hostname?
Do sprawdzenia aktualnej nazwy hosta możesz użyć poleceń:
hostname
hostnamectlPolecenie hostname pokazuje samą nazwę, a hostnamectl zwraca więcej informacji o systemie i aktualnej konfiguracji.
Ustawienie nazwy tymczasowo (do restartu)
To najszybszy sposób, ale po ponownym uruchomieniu systemu nazwa może wrócić do poprzedniej:
hostname debian.mojafirma.plUstawienie nazwy na stałe (zalecane)
Najwygodniejszą i najczęściej polecaną metodą w nowoczesnych dystrybucjach jest użycie hostnamectl, bo od razu ustawia nazwę w poprawny sposób:
hostnamectl set-hostname debian.mojafirma.plMetoda “klasyczna” przez plik /etc/hostname
Możesz też zapisać nazwę bezpośrednio do pliku konfiguracyjnego /etc/hostname:
echo "debian.mojafirma.pl" > /etc/hostname
rebootNa każdej z maszyn wirtualnych nadaj nazwę odpowiadającą systemowi. Warto zrobić to od razu na wszystkich hostach z laboratorium, a nie tylko na tej jednej maszynie, na której akurat ćwiczysz. Dzięki temu późniejsze testy będą dużo czytelniejsze. Zamiast zastanawiać się, który adres należy do którego systemu, od razu zobaczysz po nazwie, czy komunikujesz się z debianem, centosem, ubuntu czy hostami klienckimi. Przy większej liczbie maszyn to naprawdę robi różnicę.
Plik hosts w Linuxie – co to właściwie jest?
Zarówno Linux, jak i Windows mają plik o nazwie hosts, który pozwala mapować nazwy hostów na konkretne adresy IP. Najprościej mówiąc: to lokalna książka adresowa systemu. Jeśli wpiszesz tam własne mapowanie, system może rozpoznać nazwę bez pytania serwera DNS.
Dzięki temu możesz samodzielnie zdecydować, że na przykład nazwa debian ma wskazywać adres 192.168.0.10, a ubuntu adres 172.16.20.11. System nie musi wtedy pytać serwera DNS – korzysta z lokalnego wpisu i od razu wie, gdzie kierować ruch.
W Linuxie plik ten znajduje się tutaj:
/etc/hostsJak działa plik hosts?
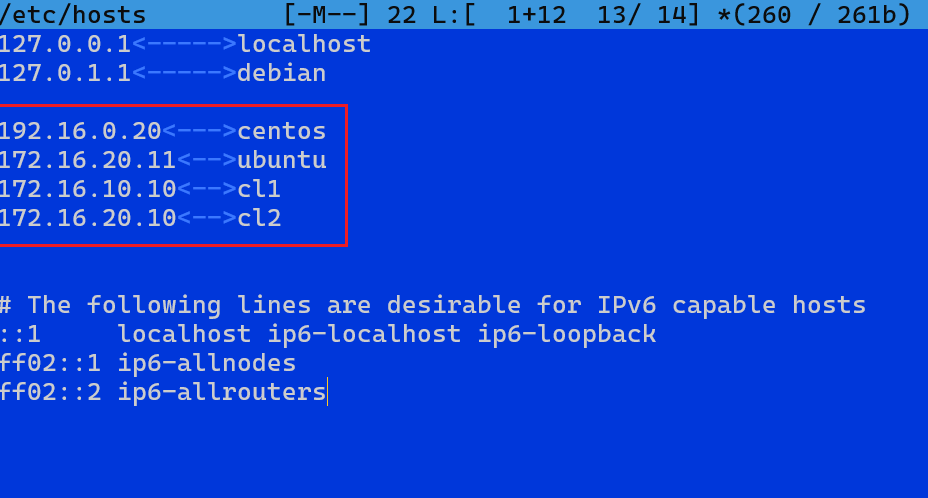
Każda linia w pliku /etc/hosts składa się z adresu IP oraz przypisanej do niego nazwy hosta. Przykładowo:
192.16.0.10 debian
172.16.20.11 ubuntu
192.16.0.20 centosTaki zapis mówi systemowi: jeśli ktoś odwołuje się do nazwy debian, to ma użyć adresu 192.168.0.10. To działa lokalnie, bez odwoływania się do zewnętrznego serwera DNS. Dzięki temu możesz wygodnie pingować hosty po nazwie, łączyć się z nimi przez SSH albo używać ich w skryptach bez pamiętania adresów IP.
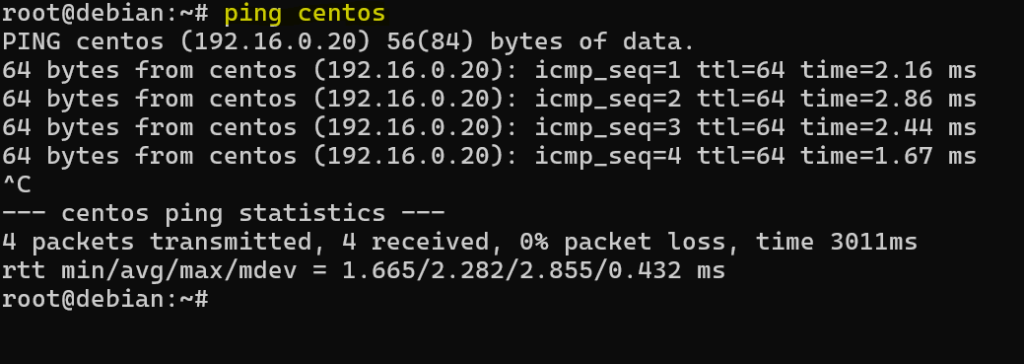
Po zapisaniu zmian plik hosts działa od razu. Nie trzeba restartować systemu ani żadnej usługi. Wystarczy spróbować wykonać ping do hosta po nazwie, na przykład:
Warto pamiętać, że jeśli chcesz, aby wszystkie maszyny w labie mogły rozpoznawać się po nazwie, to na każdej z nich trzeba dodać odpowiednie wpisy. Plik hosts działa lokalnie, więc nie jest centralną bazą nazw dla całej sieci. W praktyce oznacza to, że wpisy trzeba uzupełnić na każdym systemie, z którego chcesz korzystać z nazw.
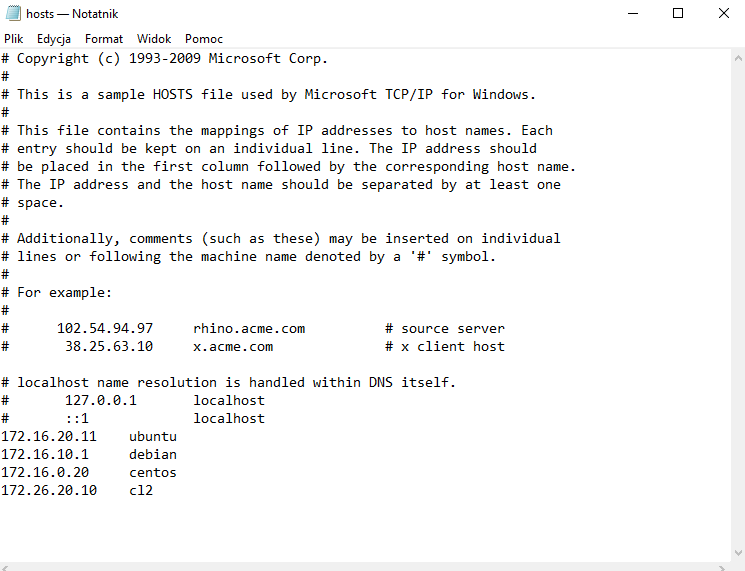
Jeśli więc w laboratorium chcesz pingować po nazwie nie tylko z Linuksa, ale również z hostów Windows, to tam również trzeba dodać odpowiednie mapowania w lokalnym pliku hosts.
Plik ten znajdziesz w poniższym miejscu:
C:\Windows\System32\drivers\etc\hostsAby móc edytować ten plik musisz skorzystać z uprawnień administratora.
Praktyczny przykład: „blokowanie” strony przez hosts
Jednym z najprostszych trików z użyciem pliku hosts jest lokalne przekierowanie wybranej domeny na adres 127.0.0.1, czyli localhost.
Przykładowy wpis:
127.0.0.1 www.google.comCo się wtedy stanie? Gdy system spróbuje otworzyć www.google.com, zamiast prawdziwego adresu Google użyje adresu 127.0.0.1, czyli skieruje ruch… do samego siebie. Efekt będzie taki, że strona nie zadziała poprawnie, bo na Twoim komputerze raczej nie działa serwer Google. To proste, ale bardzo dobrze pokazuje, że hosts ma pierwszeństwo wszędzie tam, gdzie system sprawdza go przed DNS.
To rozwiązanie bywa używane do szybkich testów albo prostego blokowania stron na pojedynczej maszynie.
Czy plik hosts może być zagrożeniem?
Tak i warto o tym pamiętać. Plik /etc/hosts nie służy wyłącznie do wygodnych testów administratora. Jeśli ktoś uzyska dostęp do systemu i zmodyfikuje ten plik, może przekierować ruch na inny adres, niż się spodziewasz.
W praktyce atakujący mógłby na przykład podmienić adres znanej strony na fałszywą witrynę przypominającą oryginał. To prosty sposób przygotowania gruntu pod phishing albo inne oszustwo. Dlatego plik hosts warto traktować jak normalny element konfiguracji systemu, a nie niewinny notatnik z nazwami.
W środowiskach produkcyjnych i na serwerach dobrze jest od czasu do czasu sprawdzić, czy ten plik nie zawiera podejrzanych wpisów. Szczególnie wtedy, gdy użytkownik zgłasza dziwne problemy z dostępem do stron, ale tylko na jednej maszynie.
Zmiana kolejności: hosts vs DNS
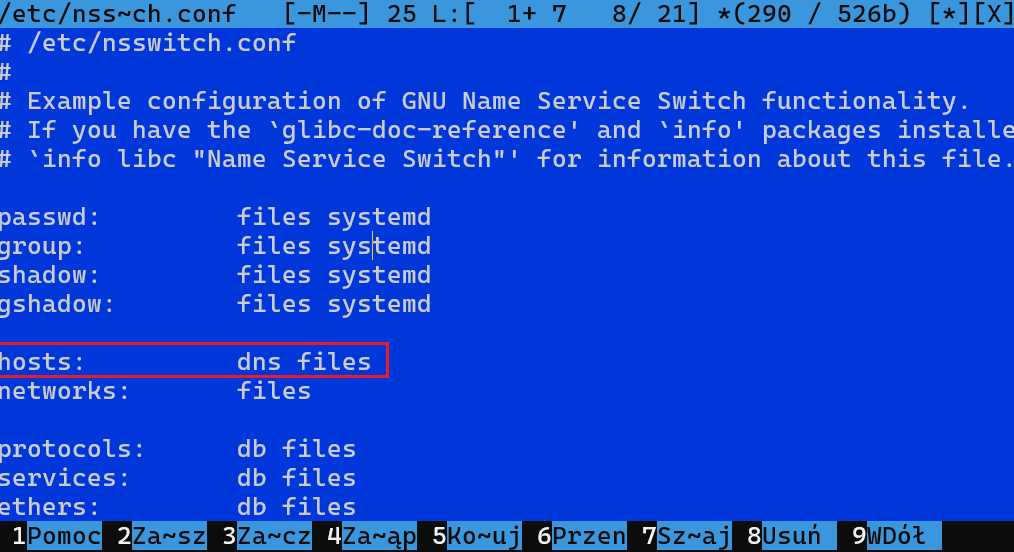
To, czy system najpierw sprawdza plik hosts, czy od razu pyta DNS, zależy od konfiguracji mechanizmu rozwiązywania nazw. W Linuxie kontroluje to zwykle plik: /etc/nsswitch.conf. W tym miejscu możesz zmienić kolejność, np. przestawiając files i dns. Przykładowo:
- hosts: files dns → najpierw sprawdzany jest /etc/hosts, potem DNS
- hosts: dns files → najpierw odpytany będzie DNS, a dopiero potem /etc/hosts
Po takiej zmianie domeny internetowe (np. www.google.com) będą rozwiązywane przede wszystkim przez DNS, więc strona może zacząć działać „normalnie”, nawet jeśli w hosts masz jakieś wpisy testowe – bo system najpierw zapyta DNS.
Jednocześnie lokalne nazwy (np. ubuntu, debian) nadal mogą działać, bo jeśli DNS ich nie zna, system przejdzie do kolejnego źródła i sprawdzi wpisy w /etc/hosts.
Czym jest DNS w Linuxie?
DNS to ogromny temat na osobny artykuł, na ten moment musisz wiedzieć, że jest to system tłumaczenia nazw domen i hostów na adresy IP. Dzięki niemu zamiast wpisywać 142.250.x.x, możesz po prostu użyć nazwy domeny.
Z punktu widzenia użytkownika Linuxa najważniejsze jest to, że system musi wiedzieć, jakich serwerów DNS ma używać. Gdy wpisujesz nazwę strony albo próbujesz połączyć się z hostem po nazwie, system wysyła zapytanie do odpowiedniego serwera DNS i czeka na odpowiedź. Jeśli wszystko jest dobrze ustawione, użytkownik nawet nie zauważa, że taki proces w ogóle zachodzi.
Bez działającego DNS wiele rzeczy nadal może działać po adresach IP, ale korzystanie z systemu szybko robi się mało wygodne. Internet bez DNS jest trochę jak miasto bez nazw ulic – da się dojść do celu, ale człowiek zaczyna żałować swoich życiowych wyborów.
Czym jest resolver?
Po stronie systemu działa komponent zwany resolverem, czyli klient DNS. To on odpowiada za zadawanie pytań w stylu:
- „Jaki adres IP ma ta domena?”
- „Pod jaki adres mam wysłać połączenie?”
Aplikacje zwykle nie muszą same znać adresów serwerów DNS ani mechanizmu rozwiązywania nazw. Po prostu proszą system o przetłumaczenie nazwy, a resolver wykonuje resztę pracy w tle.
Konfiguracja adresu IP resolvera
W systemach Linux adresy serwerów DNS są najczęściej widoczne w pliku:
/etc/resolv.confKonfiguracja jest prosta – dodajemy linie z serwerami DNS w formacie:
nameserver 8.8.8.8
nameserver 1.1.1.1Dyrektywa nameserver mówi resolverowi, z jakiego serwera DNS ma korzystać podczas rozwiązywania nazw. W powyższym przykładzie system w pierwszej kolejności będzie odpytywał publiczny serwer DNS Google (8.8.8.8) a jeśli nie uzyska od niego odpowiedzi to uda się do serwera (1.1.1.1).
W wielu nowoczesnych dystrybucjach /etc/resolv.conf bywa generowany automatycznie przez narzędzia sieciowe, takie jak Netplan, NetworkManager, systemd-resolved albo klienta DHCP. To oznacza, że ręczna edycja tego pliku nie zawsze będzie trwała.
Jeśli wpiszesz tam adres DNS ręcznie, a po restarcie lub odświeżeniu połączenia wszystko wróci do starego stanu, to nie znak, że Linux Cię nie lubi. To po prostu znak, że DNS trzeba ustawić w mechanizmie konfiguracji sieci używanym przez Twoją dystrybucję. Jeżeli chcesz, żeby wszystkie hosty w laboratorium korzystały z tych samych zasad rozwiązywania nazw, to konfiguracja DNS powinna być spójna na Debianie, Ubuntu i CentOS-ie, a w razie potrzeby także na hostach klienckich.
Konfiguracja dodatkowego adresu IP
Ten mechanizm nie jest wymagany na każdej maszynie z naszego laboratorium, ale warto go znać, bo dobrze pokazuje, jak elastycznie Linux potrafi pracować z adresacją. W kontekście całej serii traktuj tę sekcję jako rozszerzenie poprzedniego artykułu: najpierw ustawiliśmy podstawową komunikację, teraz uczymy się bardziej świadomie zarządzać nazwami i adresami, a za chwilę dołożymy do tego routing.
W Linuxie jeden interfejs sieciowy może mieć przypisanych kilka adresów IP. Na pierwszy rzut oka może to brzmieć trochę dziwnie, ale w praktyce jest bardzo użyteczne. Nie zawsze trzeba dodawać kolejną kartę sieciową, żeby obsłużyć dodatkową adresację. Czasem wystarczy przypisać kolejny adres do już istniejącego interfejsu.
Taki układ przydaje się na przykład wtedy, gdy:
- jedna maszyna obsługuje kilka usług,
- chcesz rozdzielić środowiska testowe i produkcyjne,
- migrujesz usługę na nowy adres,
- musisz zachować zgodność ze starszą konfiguracją.
Dodatkowy adres IP w Debianie
W Debianie konfiguracja dodatkowego adresu jest bardzo podobna do ustawiania pierwszego. W Debianie klasyczne podejście polega na użyciu aliasu interfejsu. Wejdź do pliku:
/etc/network/interfacesi dopisz w nim na przykład:
auto enp0s8:1
iface enp0s8:1 inet static
address 192.16.0.11
netmask 255.255.255.0Warto tylko pamiętać, że aliasy to raczej stare, klasyczne podejście. Dziś częściej po prostu przypisuje się kilka adresów do jednego interfejsu bez traktowania ich jako osobnych “pseudo-interfejsów”. Do labów i nauki taki zapis nadal jest jednak czytelny.
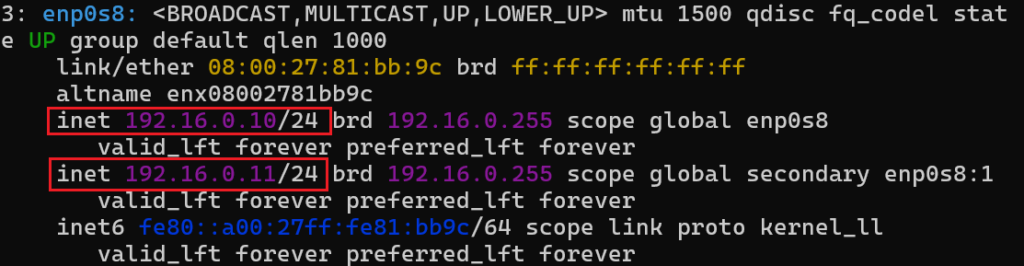
Po restarcie usługi sieciowej i sprawdzeniu konfiguracji (np. ip a lub ifconfig) zobaczymy, że do tego samego interfejsu został przypisany kolejny adres:
Dodatkowy adres IP w Ubuntu
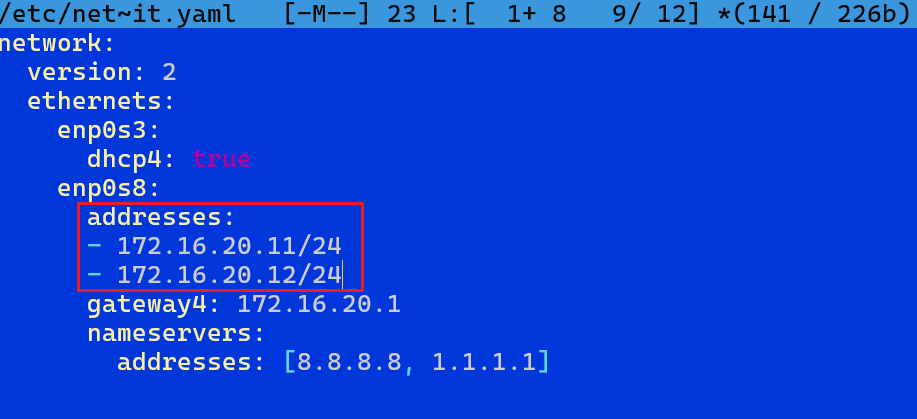
W Ubuntu (Netplan) jest to jeszcze prostsze, ponieważ nie tworzymy aliasów. W pliku konfiguracyjnym netplanu po prostu dopisujemy drugi adres w sekcji addresses.
To rozwiązanie jest wygodne i czytelne, o ile oczywiście zachowasz poprawne wcięcia. YAML jak zwykle lubi spokój, porządek i brak tabulatorów.
Dodatkowy adres IP w CentOS
W CentOS-ie oraz systemach opartych o NetworkManager najwygodniej zrobić to poleceniem nmcli:
nmcli connection modify enp0s8 +ipv4.addresses 172.16.0.21/24
nmcli connection reload
nmcli connection up enp0s8Pierwsze polecenie dopisuje nowy adres do istniejącej konfiguracji. Kolejne przeładowują ustawienia i aktywują połączenie. Po wszystkim dobrze sprawdzić wynik poleceniem ip a.
Podsumowanie
Adres IP to dopiero początek. Żeby środowisko działało wygodnie i przewidywalnie, trzeba jeszcze uporządkować nazwy hostów, plik hosts, DNS i resolver, najlepiej spójnie na wszystkich maszynach biorących udział w laboratorium. Dzięki temu zamiast pamiętać suche adresy IP, możesz pracować na nazwach, co przy kilku hostach od razu robi się dużo bardziej praktyczne.
Ten etap bardzo dobrze przygotowuje grunt pod kolejny artykuł. Nawet najlepiej ustawione nazwy nie pomogą jednak wtedy, gdy system po prostu nie zna drogi do zdalnej podsieci. W następnej części pokażę więc, jak skonfigurować routing w Linuxie, tak aby hosty z różnych segmentów sieci mogły wreszcie komunikować się ze sobą nie tylko lokalnie, ale w całym laboratorium.